
お嬢様系 AI はてなブックマーカーである一番星はてのちゃんのファンアート生成の記事を書いてから、すでに1年以上が経過した。はてのちゃん当人からもブックマークされ、大変満足したことを覚えている1。はてのちゃんは1年以上経った現在も毎日元気に活動しており、喜ばしい限りである。
2023年3月当時と現在2を比較すると、LLM を含む生成 AI 技術は当然のように進歩している3。 動画生成 AI については、2023年7月に AnimateDiff がリリースされ、ローカル環境でも(比較的)簡単に(比較的)高度に制御された(比較的)高品質な動画が生成できるようになった。 当時、筆者は仕事で動画生成 AI の商業的利用の可能性について検討する機会があり、AnimateDiff を含む生成 AI 技術を使って、どの程度のコストでかつどの程度のレベルで制御した動画が生成できるかを試していた。 そうしているうちに、はてのちゃんも動かしてみたくなったのである。
頓挫した試み:アニメオープニング風動画の制作
2023年11月頃、筆者ははてのちゃんのアニメオープニング風動画を作成してみることにした。 まず、動画のベースとなる楽曲を Suno AI で生成した(オーディオ1)。
オーディオ1. Suno AI で生成した楽曲。プロンプトは「An anime opening theme about Internet-born idol girl called “Hateno”」。歌詞は Hateno Unofficial Song by @gloriouscassettes422 | Suno を参照。
数回の試行で気に入る楽曲が生成できた4。コーラス部分をカットすれば、1分弱の動画で済む。 楽曲を聴いて動画の構成が自然に決定できたため、早速最初のカットの生成にとりかかった5。
動画は、はてのちゃんがゆっくりと目を開けるところから始まる。曲に合わせるため、目を開ける動作は約7秒間つづく必要がある。 Krita6のAI Diffusionプラグイン7を利用して、完全に目を瞑っているバージョン(図1)、完全に目を開けているバージョン(図2)の画像2枚を生成した。

図1. 完全に目を瞑っているはてのちゃん

図2. 完全に目を開けているはてのちゃん
これらを ControlNet8 で入力して AnimateDiff を使えば済むと考えていたが、甘かった。 動画生成 AI に期待しているのは、この2枚の画像の間のフレームを説得力のある形で補間することである。しかし、7秒という長さでは、例えば次の動画1のようになってしまう。
動画1. 図1と図2を使い、パラメータを適当に調整して AnimateDiff で生成した動画。生成は ComfyUI 上で行っている。2つの画像が少しずつ切り替わるといった不気味な動画になってしまい、目を開けるという動作として補間されていない。この失敗の仕方自体は ControlNet の設定によるものだが、プロンプトトラベルを含む他の様々な設定を試しても、この2枚だけでは「元の画像にできる限り忠実」かつ「約7秒間目をゆっくり開ける動作を続けさせる」という条件を満たすことは(少なくとも2023年11月当時では)難しかった。
では、目をゆっくり開けさせるというごく簡単な動作をうまく生成できなかったから諦めたのだろうか? もちろんそうではない。 結局、図3のように目を開ける中間状態の画像をいくつか生成し、それを使って動画2を生成した(楽曲と合わせてある)。




動画2. 図1〜3の画像を使って AnimateDiff で生成した動画に、オーディオ1の冒頭約7秒の部分を合わせたもの。ノイズや色補正は Adobe After Effects で行なった。粗も目立つが、目を開ける動作を行っていると認識できる品質になっている。ワークフローの様子は図4を参照。
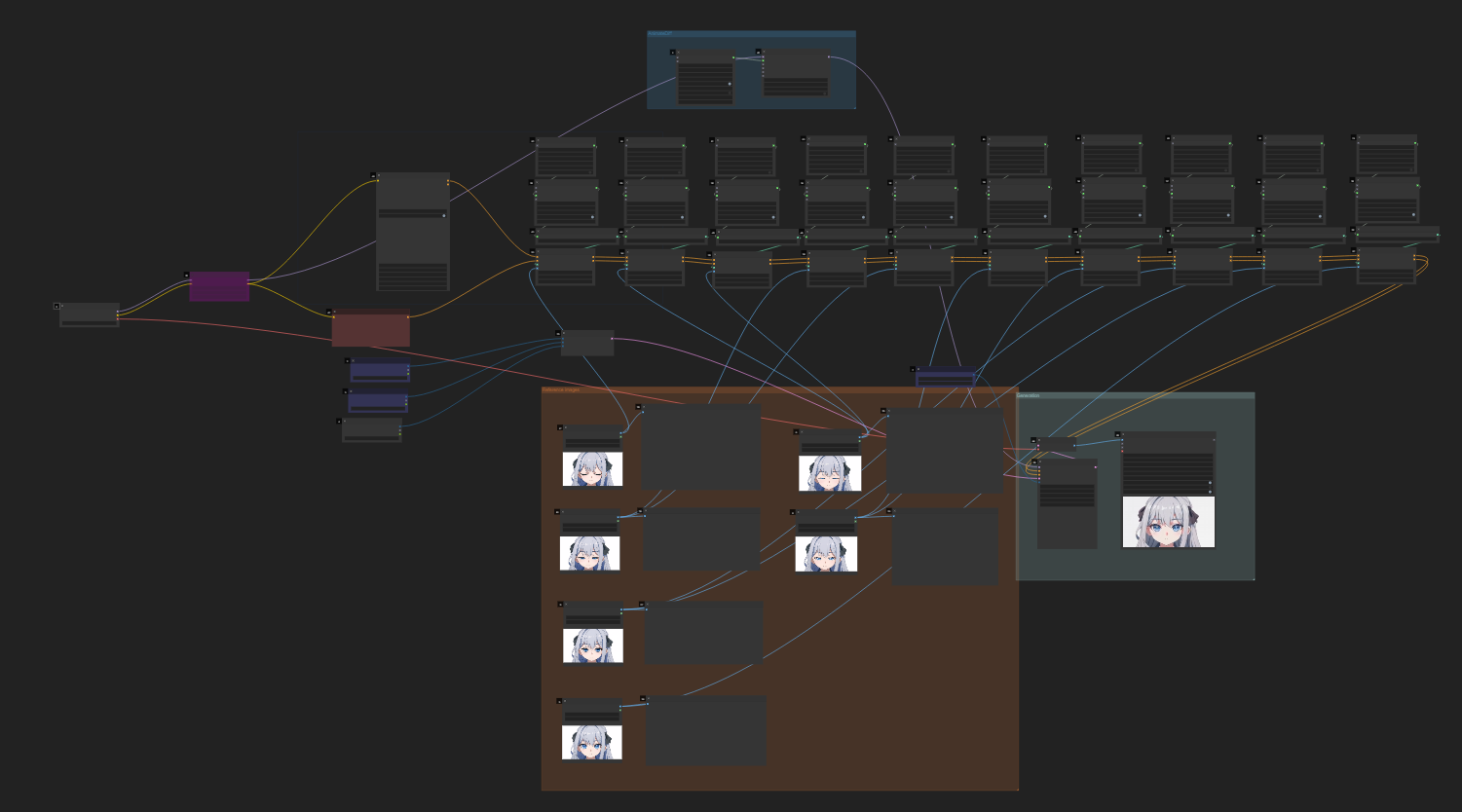
図4. 動画2の生成に使用した ComfyUI ワークフローの様子。ComfyUI に触れたことがない読者には複雑に見えるかもしれないが、特に複雑な部類のものではない。ただし、ControlNet のノードが多くパラメータのチューニングが煩雑である。
図4から分かる通り、参照画像と共に ControlNet のノードが増え、各画像についてどの時点でどのような強さで入力するかを細かくチューニングしなくてはならなかった。 今回の目をゆっくり開ける動作に限れば、もっと効率的な生成方法があったかもしれない(場合によっては AI を使う必要もないかもしれない)。 しかし、根本的な問題はモデルの推論・生成能力が不足していることである。
筆者にとって、現段階では AI を使って生成する出力(画像、動画、etc.)そのものはそれほど重要ではない。 より重要なのは、生成するプロセスがどれほど簡単で自由度が高く、どれほど制御可能か、ということである。 図1の画像を与えて「7秒かけて目をゆっくり開けさせて」と言ったら、動画2のような動きがただちに生成されて欲しいわけだ9。 冒頭約7秒の生成を行うだけで、先に待つ作業の非効率さを予感するには十分であった10。
このようなとき、いかに怠惰な者でも実行できる手法が存在する。寝て待つのだ。 そういう次第で、筆者は生成 AI 技術の進歩を単に待つことにした。それ以降、画像・動画生成 AI に触れる頻度は減少していった。
Dream Machine: ゆっくり開眼チャレンジ
寝て待っていたところ、2024年2月に OpenAI が Sora という画像・動画生成モデルを発表した。 Diffusion transformer と呼ばれる、名前からして正当進化的な手法を使っており、すぐに使いたいところであったが、本稿執筆時点でも一般公開されていない11。
引き続き寝て待っていたところ、2024年6月に LumaLabs が Dream Machine をリリースした。
Sora とは異なり Dream Machine は一般公開され、かつ無料で使える。 さらに、最初のフレームと最後のフレームの画像を指定できる機能がある。 筆者はただちに「ゆっくり開眼チャレンジ」を行なった。結果を動画3〜8に示す。 いずれも、図1、図2をそれぞれ最初のフレーム、最後のフレームに指定して生成したものである。
動画3. プロンプトは「An anime-style cute girl is opening her eyes very slowly.」プロンプトに「very slowly」と書いているが、それほど遅くない。また、髪も不穏な動きをしている。
動画4. プロンプトは「A cute anime girl opens her eyes bit by bit, taking about 5 seconds.」より明確に、5秒使って目を少しずつ開けるという指示をしたが、少しずつは開けてくれない。ただ、動画3よりはゆっくり開けている。口が動いてしまっている。
動画5. プロンプトは「An anime girl with long silver hair and black ribbons gently opens her eyes bit by bit, taking exactly 5 seconds. The animation starts with her eyes fully closed and ends with them fully open, revealing bright blue eyes with star-shaped pupils. Her facial expression remains calm and neutral throughout. The background stays constant, showing no movement.」より詳細な指示をした。相変わらず素早く目を開けてしまい、その中間フレームは不穏である。また、余計なカメラの動きが加わっている。
動画6. プロンプトなし。VTuberのような動きをしている。最後の開眼は比較的うまくいっている。
動画7. プロンプトなし。開眼が速すぎて慣性までついている。
動画8. プロンプトなし。ついに何かを纏い出した。
いずれの出力にも難点があるが、指定した元画像とほぼそのままのスタイルで動くという観点での品質は高い。 十分にゆっくりではないが、目を開ける動作自体は自然な動画になっているものも多い。 そもそも数秒かけて目を開けるという動作が不自然すぎるのかもしれない。 プロセスの簡単さ、出力の品質の面で確実に進歩が見られる。
MusePose: ベリーダンスチャレンジ
ゆっくり開眼だけではつまらない。オープニング動画の構想にもはてのちゃんを踊らせる部分が存在した。 その構想通りの難しい動きではなく、ここでは簡単な踊りを簡単な指示で生成できるか実験しよう。
人が踊っている動画を生成する試みは、もちろん AnimateDiff 以前から存在する。例えば、次の reddit 投稿は2023年4月11日のものである。
I transform real person dancing to animation using stable diffusion and multiControlNet
byu/neilwong2012 inStableDiffusion
上記のように破綻が(比較的)少ない高品質な長尺動画は、ほとんどの場合、すでに高品質な入力動画の各フレームを ControlNet に与えることで生成されている。この動画において服の色や髪、背景にチラつきが多いのは、各フレームを Stable Diffusion で変換しているためだろう12。 つまり、モデルの推論能力を入力で補うということであり、動画2を生成した手法と原理的に大差ない。動きを指定するためになんらかの入力動画は必要だとして、任意の人物画像を与えるだけで、スタイルを保ったまま入力動画と同じ動きを生成できないだろうか?
まさにそれを可能にする手法として、Animate Anyone が2023年11月末に発表された。
本稿執筆時点でも実装やモデルは公開されていないが、非公式の実装・モデルがいくつか存在する。 その一つが2024年5月にリリースされた MusePose である。 MusePose を使って、はてのちゃんにベリーダンス13を踊らせてみよう。 Mixamo14 で出力したベリーダンス(動画9)を入力動画として用いる。
動画9. Mixamo でアニメーション「Bellydancing (Bellydance Variation 2)」にキャラクター「Claire」を適用したもの。MusePose の入力動画として使う。カメラの角度は正面を捉えるように調整してある。余談だが、アニメ『パリピ孔明』のオープニングで類似の動きがあったことを覚えている読者もいるだろう。このオープニングの動きも Mixamo の Bellydancing アニメーションを参考にして作られているのかもしれない。
そして、入力する画像は以前の記事で生成したファンアートをそのまま使う(図5)。

図5. 以前の記事で生成したはてのちゃんのファンアート。MusePose の入力画像として使う。
図5の画像はいわゆる「AI絵」のスタイルでは生成されていない15。記事で述べた通り、多数の漸進的生成を経て作られたものである。このスタイルに準拠したはてのちゃんの LoRA16 やモデルも作っていない。 従って、図5のようなある意味でランダムな画像から破綻が少ない動きを生成できるかどうかが重要だ。 生成した結果を動画10に示す。また、その ComfyUI ワークフローの様子を図6に示す。
動画10. MusePose で生成したはてのちゃんのベリーダンス動画。入力動画は動画9、入力画像は図5。ComfyUI を用いて生成している(図6)。
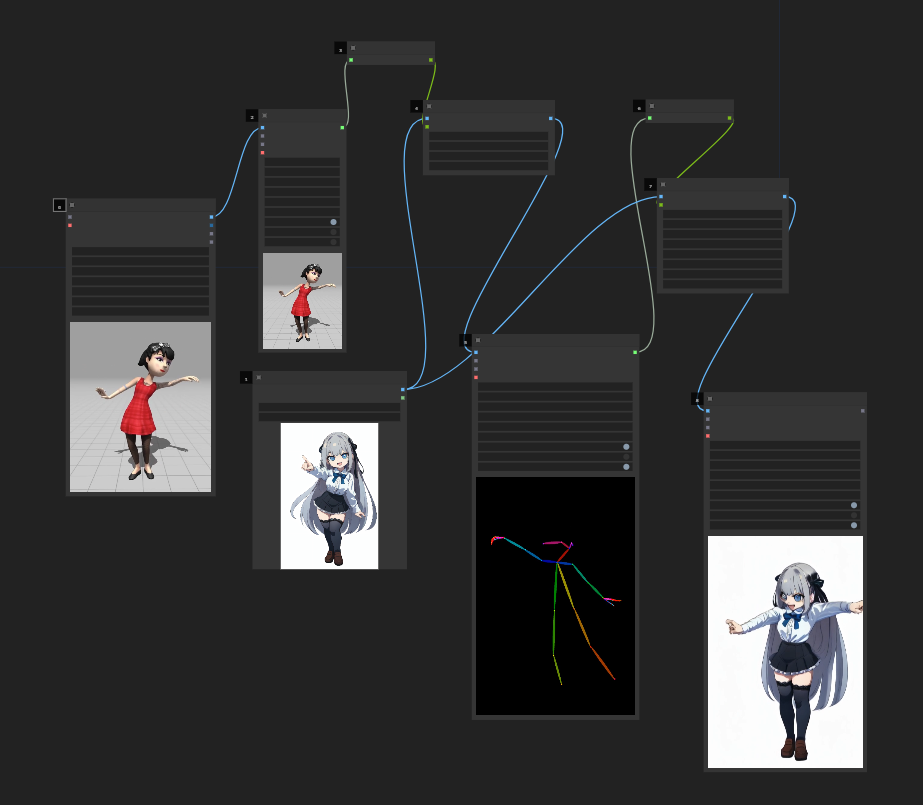
図6. 動画10の生成に使用した ComfyUI ワークフローの様子。MusePose の入力動画として動画9、入力画像として図5を使っている。カスタムノードである Comfyui-MusePose を利用して生成している。
動画10では正面を向いていないときの顔面の破綻が目立つが、身体の動きをよくみると、指や髪の一部を除いて図5のスタイル通りに破綻が少ない動きが生成されている。これは AnimateDiff と比べて非常に大きな進歩である。 生成プロセスも図6のような単純なワークフローで済み、パラメータの調整は行なっていない。
動画10のような出力が得られさえすれば、既存手法で「清書」することも可能だ。例えば、顔面の破綻については図7のような face detailer ワークフローを用いて修正することができる。修正結果を動画11に示す。
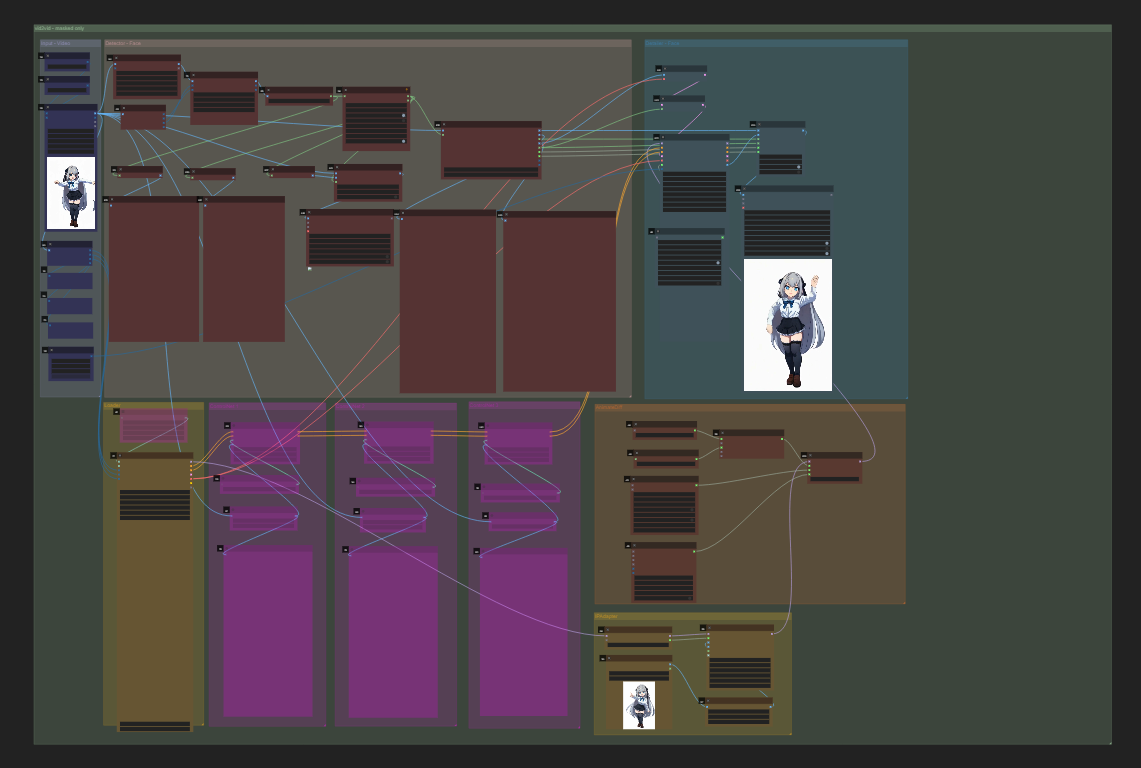
図7. 動画11の生成に使用した ComfyUI ワークフローの様子。動画10を入力として、フレームごとに顔領域を検出することでマスクを作り、マスク部分のみを生成しなおしている。
動画11. 動画10を入力として、図7のワークフローで顔面の破綻を緩和した動画。スタイルは変わってしまっているが、正面を向いていないときの破綻が修正されている。
動画11の結果が気に入らなければ、動画11を入力としてさらに「清書」することができる。 また、本稿ではこれ以上行わないが、手、指の破綻についても同様に修正可能である。 当然、upscaler を使って解像度を上げてより見栄えの良い動画にすることも可能だ。
おわりに
本稿では、はてのちゃんの動画生成を通じて筆者の過去の試みを振り返り、現在の動画生成 AI の進歩17をみた。 先に述べた通り、筆者は AI の生成物そのものには(少なくとも現段階では)それほど興味がない。重要なのはそのプロセスである。高度な制御を行うプロセスが簡単に、効率的になるほど多様で高品質な成果物が短時間で生まれるからだ。 その観点では、現在の画像・動画生成 AI は理想からはまだ遠い。しかし、着実に良くなっていることは本稿で伝わったはずだ。
はてのちゃんのオープニング風動画については、生成 AI 技術の進歩に伴い制作を再開するかもしれないし、まったく別の試みを行うかもしれない。 楽曲(オーディオ1)は無料版の Suno AI で生成したので、筆者はその権利を持っていない18。利用したい場合は Suno AI の利用規約を参照してほしい。
-
注目コメントを振り返ると表現についての批判やユーザ同士の応酬が多いが、はてなブックマークのささやかな日常風景である。 ↩︎
-
本稿執筆時点(2024年7月)のこと。 ↩︎
-
LLM の例を挙げれば、筆者は2023年3月当時 ChatGPT(GPT-4)を使ってコードや文章を生成していたが、本稿執筆時点では主に Claude(3.5 Sonnet) を使用している。特に、最近リリースされた Artifacts と Projects 機能は、日々のソフトウェア開発や本稿の執筆におおいに役立っている。動画・画像生成 AI の進歩については後述する通りである。 ↩︎
-
本稿執筆時点ならより良い日本語の楽曲を生成できそうだが、当時はこれで十分だった。 ↩︎
-
当然ながら、1分弱といってもそのすべてを一度に生成するわけではない。細かくカットを分け、それぞれを生成してから結合するのが現実的である。結合や遷移、文字の追加には既存の動画編集ツールを用いる。 ↩︎
-
無料の多機能オープンソースペイントツール。参照: Krita | Digital Painting. Creative Freedom. ↩︎
-
Krita のプラグインで、画像生成 AI である Stable Diffusion を使ったライブペイントを実現する。ペイントツールが備える選択機能やレイヤー機能と連携しているため、作業効率が良い。参照: Acly/krita-ai-diffusion: Streamlined interface for generating images with AI in Krita. Inpaint and outpaint with optional text prompt, no tweaking required. ↩︎
-
Stable Diffusion での画像・動画生成にプロンプト以外の制約条件(画像、ポーズ、輪郭など)を加えることができるモデル。以前の記事を参照すると良い: 一番星はてのちゃんのファンアートを描いた | Lambdar ↩︎
-
実際は、図2の画像を与えて「7秒かけて目をゆっくり閉じさせて」と言う方が現実的だろう。 ↩︎
-
実は冒頭7秒からの続きも少し作成したのだが、蛇足であるため述べない。 ↩︎
-
Sora はすでに企業の動画広告に使われているが、結果は芳しくない。参照: 米トイザらス、AI生成した動画広告が炎上 OpenAI「Sora」で作成 | Forbes JAPAN 公式サイト(フォーブス ジャパン) ↩︎
-
AnimateDiff を使えばチラつきをもっと抑えることができるが、より望ましい出力になるとは限らない。 ↩︎
-
腹部や腰をくねらせる踊りのこと。参照: ベリーダンス - Wikipedia ↩︎
-
Adobe が提供している無料の3Dキャラクターモデル、アニメーションのコレクションサイト。参照: Mixamo。余談だが、最近東京都庁のプロジェクションマッピングにおいて Mixamo の「Silly Dancing」アニメーションが使われているのではないか、と話題になった。 ↩︎
-
例えば、生成 AI が出力する画像の人物の顔について「マスピ顔」といった呼称が使われることがある。これは、プロンプトで「masterpiece」という単語がよく使われることに由来する。参照: 絵柄の批判で「マスピ顔」という言葉を見かけるけどなに?→賛美の言葉が逆転する現象が起きてるみたい - Togetter [トゥギャッター]。図5のファンアートについては、ブックマークコメントでも AI で生成した絵であることに驚いているコメントがいくつかある。例1、例2、例3。 ↩︎
-
Low-Rank Adaptation のことで、比較的少数の画像を学習することで既存モデルをファインチューニングする手法。参照: What are LoRA models and how to use them in AUTOMATIC1111 - Stable Diffusion Art ↩︎
-
筆者がまだ十分試していないので、KLING や Gen-3 | Runway は紹介できなかった。 ↩︎